


Section 2 introduced the maximum-likelihood method
for estimating probabilities from counts,
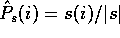 .
Maximum likelihood is asymptotically optimal as
.
Maximum likelihood is asymptotically optimal as
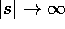 , but performs very badly for small sample
sizes, since
the encoding cost for any amino
acid not seen in the sample is
, but performs very badly for small sample
sizes, since
the encoding cost for any amino
acid not seen in the sample is 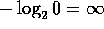 .
To avoid this infinitely high cost, we will constrain regularizers to
provide non-zero estimates for all probabilities:
.
To avoid this infinitely high cost, we will constrain regularizers to
provide non-zero estimates for all probabilities: 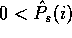 .
.
Regularizers can be viewed as making an adjustment to the sample
counts, s, to produce posterior counts, 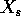 , from which we
estimate the probability:
, from which we
estimate the probability:

To get legal estimated probabilities and avoid infinite costs, the
primary constraint is 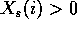 .
.
Note: there will be several different formulas given for computing
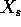 , corresponding to different regularizers.
The symbols
, corresponding to different regularizers.
The symbols 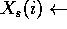 will be used for defining the
different methods.
The notations
will be used for defining the
different methods.
The notations 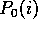 and
and 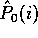 refer to the background
probabilities and their estimates (that is, the probabilities given a
sample of size zero).
refer to the background
probabilities and their estimates (that is, the probabilities given a
sample of size zero).
Once we have decided that the goal is to minimize the average encoding cost of the columns, and chosen a method to try, we can try to optimize the parameters of the method, using Newton's method or gradient descent to find parameter values at which all the first derivatives of the encoding cost are zero, and all the second derivatives are positive.
We can compute the derivatives of the encoding cost 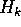 with respect to any parameter
fairly easily from
with respect to any parameter
fairly easily from 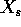 and its derivatives.
For many of the methods, the second derivative of
and its derivatives.
For many of the methods, the second derivative of 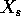 is 0 for all
the parameters, further simplifying the optimization.
For a more complete discussion of optimization, see [13].
is 0 for all
the parameters, further simplifying the optimization.
For a more complete discussion of optimization, see [13].