GPU Accelerated Particle Engine
Final Project - cmps161 - Winter '06
Daniel Keller (keller@cats)
Introduction
Modern graphics hardware possesses the ability to process large amounts of data in parallel, a capability aimed primarily at transforming and lighting large numbers of triangles in real-time. However, the programmable nature of this hardware, as well as recent extensions to the standard software interfaces to it, allow this power to be applied to a much wider range of problems. One obvious application of this power is to the problem of particle system. Particle systems consist of large quantities of independent entities which obey a basic set of rules for interaction with their environment. The independent nature of these particles makes processing them in parallel possible, and the relatively simple rules governing them can be implemented in programmable graphics hardware.
Approach
One of the primary bottlenecks involved with doing general purpose computation on GPUs is the transfer of data between main CPU memory and the GPU where it can be processed. This bottleneck is especially problematic for graphical applications which may need to transfer data and process the results in real-time. Data may be delivered to the GPU in two ways:
Vertex data
Texture data
Vertex data, position, color, normal, etc, are passed explicitly by the programmer and processed during the vertex processing stage of the pipeline. OpenGL 2.0 allows custom 'vertex attributes' to be supplied, giving the programmer much control over the data to be submitted. However, processing data in the vertex stage of the pipeline has significant disadvantages. Most current video hardware is not able to do texture reads from the vertex stage, limiting the computation to the data explicitly supplied, data can not be retrieved based on calculations occurring within the vertex shader. Also, each vertex must be processed an additional time by the fragment shader, which even if it is a simple pass-through, will incur some cost.
Texture data is supplied by the programmer independently of vertex data, and is not available in the vertex processing stage of the pipeline (e.g. in custom vertex shader). However it may be retrieved during the fragment processing stage (eg in a custom fragment shader), and thus provides the programmer with a potential way to allow his computational task to access data it depends. Because vertex data is interpolated and passed to the fragment shader, we can also save processing time by reducing the amount of vertex data to be submitted.
We will use the texture data method, in order to keep vertex-processing time to a minimum, and to maintain maximum flexibility in our computations. To do this we must setup the pipeline as follows:
Given a data array with R rows and C columns.
Pack the data into textures, the majority of hardware only supports power-of-two texture dimensions, so we may need to enforce limits on the size of the data arrays being submitted.
Setup a viewport with dimensions RxC.
Setup a 2D orthographic projection matrix viewing the region (-1, -1) to (1,1).
Setup our custom fragment shader and the stock vertex shader.
Enable 2D texturing.
Disable Z-testing
Submit a screen-sized (ie spanning (-1,1) to (1,1)) quad with texture coordinates (0,0) to (1,1).
Read back the results from the frame buffer
The fact that our viewport matches the dimensions of our data array will guarantee that our fragment shader will be called once for each item in the array. The shader may then use the interpolated texture coordinates to lookup that item in the array. In this way we can supply one set of texture coordinates, and as many data arrays as we wish (up to the number of texture units available on the hardware, commonly 8). We can also calculate the texture coordinates corresponding to other data items and look them up as well if desirable, which would not be possible in a vertex shader.
Since memory bandwidth is a precious resource, we must consider carefully how to move data to and from the GPU. The standard method, using only operations provided by core OpenGL, is to fill a texture with our data, submit it for processing, and read the results back from the frame buffer. However this is slow and undesirable if we want to operate on the data several times without needed to read it back into CPU memory (eg if we have access to OpenGL extensions allowing us to treat the texture data as vertex data for final processing, or if we want to do several small steps of Euler integration before rendering). Two notable OpenGL extensions exist to address this.
PBuffers are a platform-dependent extension which allows data to be rendered into a buffer associated with the current OpenGL context. However this data is disassociated from the depth-buffer, stencil buffers, and requires a context switch to return to normal rendering. The fact that it is available on Win32 systems only precludes it from consideration for this project.
Frame-buffer Objects (FBOs) are a more recent OpenGL extension which allow output to be diverted to a normal OpenGL texture. This extension is platform independent, does not require context switches, and integrates seamlessly with the normal OpenGL operation. FBOs allow us to attach a texture as the current output target, and swap this texture with another, without copying any memory. Thus we can allocate two textures and "ping-pong" between them: we bind one as the source of our data and the other as the result, process, and then switch them. This allows us to do all processing in the GPU memory without ever copying back to the CPU until we need the final results.
Under normal circumstances our ,fragment shader output is restricted the tuple of RGBA values which would have been written to the frame buffer (or potentially discarded if we were doing normal rendering including a Z-test). On most current hardware this tuple is stored internally as a 32bit value with 8-bits for each component. This is problematic for general-purpose computing, since it limits the total output of one processing pass to 32 bits, and assuming we supply a distinct piece of data in each of the RGBA components, each component is limited to 8 bits. Additionally, each color component is clamped to the range [0.0,1.0] before being mapped to the 8 bit value integer range [0,255]. This requires further complicates processing, forcing all input and output to be normalized to the range of unclamped values.
Fortunately another OpenGL extension exists which addresses these issues. "ATI Texture Floats" (in addition to similar extensions from other vendors) allows frame-buffer data to be stored using unclamped ieee 754 single-precision floating point values, or using a proprietary 16 bits floating point format. However this raises additional problems. Most notably, blending mode is not supported when using a floating point frame buffer. If blending is required, for example to support transparency effects, or to render a HUD or textured fonts, then it must be implemented by hand using a custom fragment shader. This requires an extra level of indirection, the frame must be rendered to a buffer, and then blended with other components onto the frame buffer, rather than being written directly to the frame-buffer. This can have a significant impact on performance.
Although we can get full precision floating point results, we are still limited to one RGBA tuple of output per rendering pass. This is addressed by yet another OpenGL extension, "Draw Buffers". This extension (now part of the core as of OpenGL 2.0) allows us to supply additional outputs from the fragment shader. These outputs may be directed to additional textures attached to our FBO, allowing us compute several values (4 RGBA tuples, so 16 floating point values, on most current hardware) in one pass.
Implementation complications
A MacBook Pro laptop containing an ATI X1600 Radeon Mobility graphics processor was purchased in order to develop and present this project. This system claims to fully support OpenGL 2.0 as well as the necessary extensions (a point which was carefully considering when choosing it). However, despite the claims made by Apple's marketing, and the underlying support of the ATI graphics card, the currently available drivers do not fully support OpenGL 2.0. Specifically, the Draw Buffers extensions is not supported. This is a relatively small problem, however several full days were wasted attempting to remedy it and to reconcile the conflicting information provided by Apple and the hardware itself. Apple claimed full support, while the driver claimed that the extensions were not available. It was eventually discovered that the extension was not implemented, but the OpenGL 2.0 core function which the extension was promoted to was provided, but this still only implemented the ability to write one value of output (i.e. the mechanism was in place, but when queried for the maximum number of possible outputs, 1 was always returned, making it useless).
This problem was addressed running multiple rendering passes, one for each desired output. This is slightly inefficient, since values may need to be recomputed and fetched from texture memory in every pass, and is cumbersome, requiring a separate shader to be written for each output father than just a single unified one.
The need for floating point results provided another unfortunate complication. Although the driver would successfully claim to be making use of floating point values when loading data into a texture attached to a FBO, results were persistently camped to [0.0,1.0]. Several days worth of effort revealed that this was due to a requirement, at the OS level, of requesting a floating point frame-buffer when creating the initial window to be drawn to.This was quite unexpected, and unfortunately, not supported by SDL, which was being used to maintain cross-platform compatibility.
This was fixed by patching SDL to supply the correct flags to the underlying windowing system. At least if in all other ways this project is a failure, SDL has now infinitesimally benefited from it. :)
Several additional problems were caused by undocumented behavior in the graphics drivers, presumably due to the immaturity of apple's drivers. For example, while it was possible to read from a texture while it was bound to a FBO, it was not possible draw it while bound to a different FBO. Most notably the extensions required to render directly from the textures loaded into the FBO was non-functional, requiring a copy back to cpu memory every frame.
Use
The executable named 'gibby' may be built using the standard GNU make. This requires a custom version of SDL1.2 which has been included. The standard distributions of SDL_ttf and GLEW are also required. Once built, gibby may be run from the command line, which accepts the following arguments:
-t Enters test mode. A build-in effect is run, and blending mode may be turned on or off to demonstrate its effect on the framerate
-w X X may be any power-of-two number requesting that the effect operate on X^2 particles
-T Disable floating point texture framebuffer, will result in some modes not working
-e Effect Run the effect named Effect. Effects are composed of GLSL source files which control the logic governing the effect. Each effect must have position and color data, and can optionally have additional data. Data is created initially using the 'seed' shader, and updated per-frame using the 'tick' shader. Each shader has access to all the othere data components, and it's output will be the new value for that component in the next frame. Additiomally access to random data, the current frame number, and the current time and time-delta since the last frame are available. See the included bounce files for examples.
The following files are loaded for an effect:
Effect_pos_seed.gls - the seed logic for position data (optional)
Effect_pos_tick.gls - the per-frame logic for updating position (required)
Effect_col_seed.gls - the seed logic for position color (optional)
Effect_col_tick.gls - the per-frame logic for updating color (required)
Effect_vel_seed.gls - the seed logic for velocity data (optional)
Effect_vel_tick.gls - the per-frame logic for velocity position (required)
Effect_AuxA_seed.gls - the seed logic for auxilary data (optional)
Effect_AuxA_tick.gls - the per-frame logic for auxilary position (required)
AuxB, AuxC, etc may follow, up the the number of texture units supported by yours hardware.
Once running, the camera may be moved with the arrow keys. Additionally, the following keys work:
i - cycle implmentations
b - toggle blend mode, only works with some implmentations
d - toggle drawing (but still update the world)
t - toggle text
Results
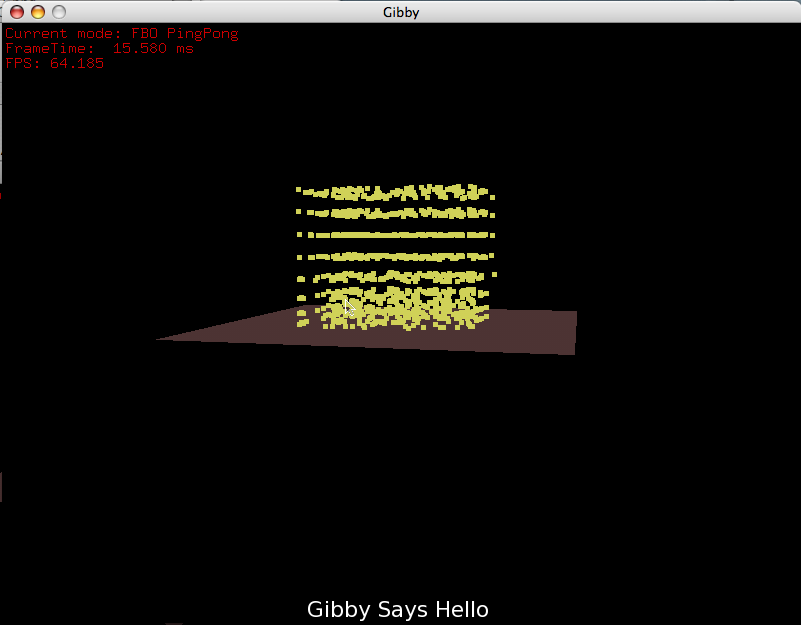
A view from the side of some effect
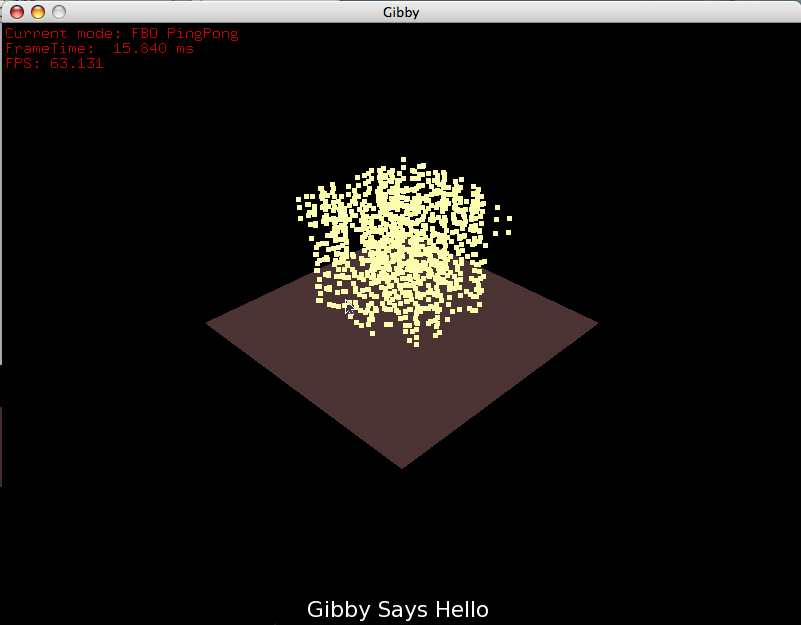
A later view from of the same effect
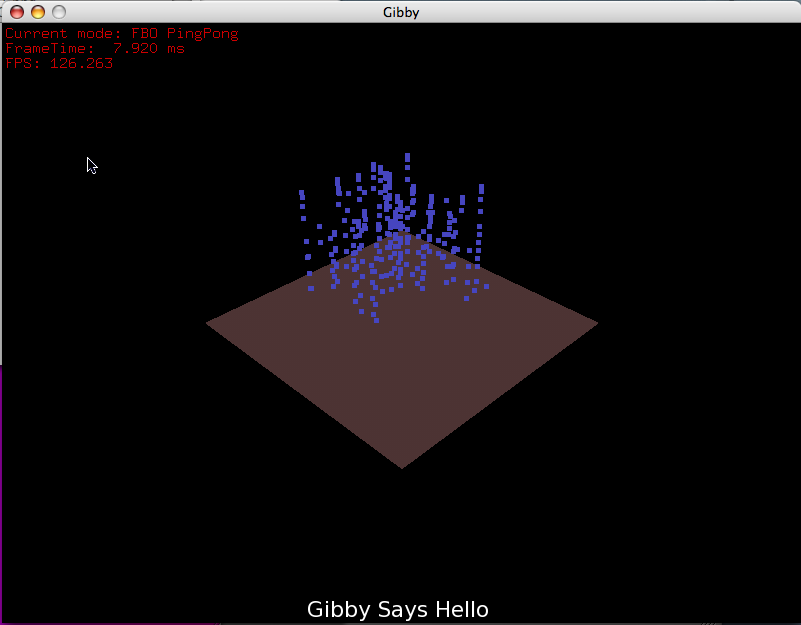
A bit later still
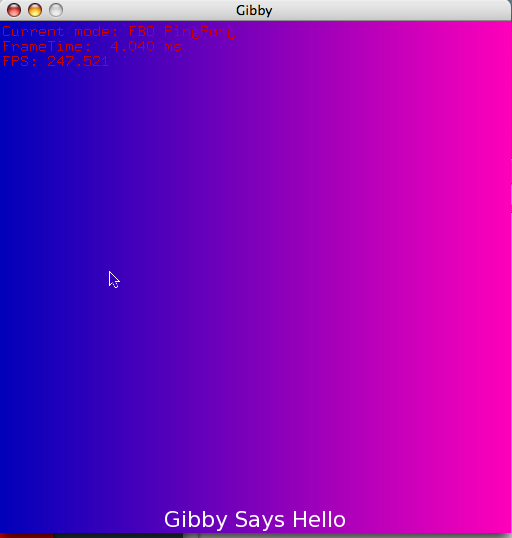
Test mode, with manual blending enabled, causing the text at the bottom of the screen to be overlayed on the background.
Test mode with blending off, causing the area behind the font texture to be obscured.
Video - nonexistent...
After many attempt to find a program that would capture outpug from gibby in a video, I have concluded that such a thing is not possible using standard Os X tools. All tools capture the area surrounding the window, but Os X stops drawing the window shortly after the video starts recording, making it impossible to capture more than a second or two. This may be due to the use of the floating point pixel buffers.